ファセットの使い方
Overview
ファセットは OpenRefine の最も強力な機能の 1 つです ― ダイヤモンドのロゴはそこから来ています。
ファセットを使うと、パターンや傾向を視覚化できます。ファセットとはある列に含まれるデータの変動の「見方(アングル)」で、たとえばアンケートで「強く賛成」〜「強く反対」まで 5 段階の回答があれば、それら 5 つの回答がテキストファセットを構成し、各回答が何件あるかを示します。
ファセットブラウジングはデータ全体の大局的な把握(賛成派が多いか反対派が多いか)だけでなく、特定のサブセットに絞ってさらに詳しく調べる(反対と答えた人は他にどんな回答をしているか)ことにも役立ちます。
通常、特定の列にファセットを作成します。作成されたファセットは Facet/Filter タブの左側に表示され、表示された項目をクリックするとその条件に合致するレコードだけが表示されます。「除外(exclude)」をクリックすれば一致しない行だけが表示され、「含める(include)」を複数押すと複数の値を同時に選択できます。
An example
次の例でファセットとフィルターを体験できます。以下の表をコピーし、プロジェクトを作るときに を使って貼り付けてください。数値ファセットを使えるように「Attempt to parse cell text into numbers」をオンにしておきましょう。
Wikidata の例クエリから上位 10 都市を取り出し、GPS 座標を削除して国名を追加しました。
| cityLabel | population | countryLabel |
|---|---|---|
| Shanghai | 23390000 | People's Republic of China |
| Beijing | 21710000 | People's Republic of China |
| Lagos | 21324000 | Nigeria |
| Dhaka | 16800000 | Bangladesh |
| Mumbai | 15414288 | India |
| Istanbul | 14657434 | Turkey |
| Tokyo | 13942856 | Japan |
| Tianjin | 13245000 | People's Republic of China |
| Guangzhou | 13080500 | People's Republic of China |
| São Paulo | 12106920 | Brazil |
もっとも人口の多い都市が属する国を知りたいときは、“countryLabel” 列にテキストファセットを作成すると、列内に出現する文字列とその件数(カウント)が一覧で表示されます。
サイドバーに国名とカウントが表示され、アルファベット順やカウント順に並べ替えられます。カウント順で上に並んでいれば、最も多く人口上位都市を抱える国が分かります。
| Facet | Count |
|---|---|
| People's Republic of China | 4 |
| Bangladesh | 1 |
| Brazil | 1 |
| India | 1 |
| Japan | 1 |
| Nigeria | 1 |
| Turkey | 1 |
特定の国について詳しく見たい場合は、その国をクリックすると一時的に該当する行のみでデータが絞り込まれます。
たとえば “People’s Republic of China” をクリックすると「10 rows」表示が「4 matching rows (10 total)」に変わり、データグリッドには選択された 4 行のみが表示されます。行番号は元のまま(ここでは #1、2、8)です。
元のデータセットに戻したい場合は かファセット横の小さな “exclude” をクリックします。中国とインドの両方に絞りたいなら、それぞれのファセットで “include” を押すと 5 行(#1、2、5、8、9)が表示されます。
人口情報を使ってさらに絞り込むことも可能です。人口が数値なので数値ファセットを作れば、値の範囲でフィルターできます。
数値ファセットは列の最小値〜最大値のスケールを示し、範囲の最小/最大をドラッグして調整できます。上図の例では 2,000 万以上を選ぶと、元の 10 行から 3 行だけが残ります。
その状態で国名のテキストファセットを見ると表示項目は 3 行分だけに減り、総数 10 行のファセットではなく現在フィルターされた 3 行に基づいた表示になっていることが分かります。
ファセット同士を組み合わせることもできます。たとえば人口 2,000 万以上の中国の都市に絞るには、その両方をクリックすれば 2 行が残ります。
Things to know about facets
ファセットを適用すると、プロジェクトグリッドのヘッダー に “matching rows” が表示されます。ファセットが有効な状態で からデータをコピーすると、多くのエクスポートオプションは一致した行のみを出力し、すべての行を出力しません。
OpenRefine にはデフォルトのファセットが複数ありますが、最も強力なのは自分で式を使って作成するカスタムファセットです。expressions を使ってデータを変換し、狙った対象を正確に絞り込めます。
ファセットはプロジェクトと一緒に保存されませんが、現在の状態へのリンクを保存できます。プロジェクト名横にある を探してください。
ファセット一覧の右側にある “change” ボタンを押すと、該当列の式を編集できます。
サイドバーに表示されるファセットのボックスはサイズ変更や並べ替えが可能です。タイトルバーをドラッグ&ドロップして順序を入れ替えたり、テキストファセットの下端をドラッグして高さを変えたりできます。
特定の操作はファセットの状態を無視します。ファセットでフィルタリング中に以下の操作を行うと、フィルター済みのサブセットだけでなく、テーブル全体の該当データ(列や行)に対して操作が適用されます:
- 列の移動・削除・名前変更・並べ替え
- 複数値セルの分割・結合
- 行の再順序付け
- 転置(列 ⇔ 行、キー/バリュー列による列化)
Text facet
“text” データ型の列にテキストファセットを作るには、列のドロップダウンから → を選びます。作成されたファセットはアルファベット順に並び、カウント順にもできます。
テキストファセットは単純で、列のセルの内容をそのまま集計し、近似値や誤字を自動的に補正しません。
ファセット表示に出た項目を編集するには、ファセットにマウスを重ねて表示される “edit” ボタンをクリックし、新しい値を入力します。これにより列内のすべての一致するセルが一括で変更されます。誤字や余分な空白を修正するのに便利です。さらに クラスタリング を使えば、ファセット内の “Cluster” ボタンから自動的に類似セルをまとめて、まとめて書き換えることもできます。
テキストファセットは最大 2,000 件の項目を表示します。必要なら 設定画面 で上限を変更できますが、ブラウザの動作が遅くなる可能性があります。適用したファセットで上限を超える項目数があると、上限を増やすオプションが表示され、その設定が永続的に保存されます。
各ファセットの項目一覧とカウントはタブ区切り値としてコピーできます。ファセットの左上にある “X choices” リンクをクリックすると、項目とカウントが TSV でコピーされ、小規模な集計表を作る際に便利です。
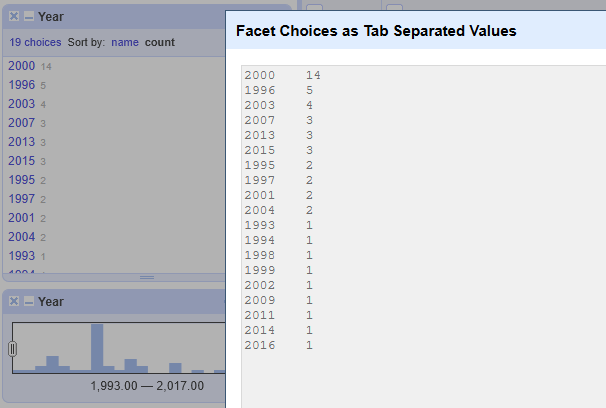
Numeric facet

テキストファセットが文字列の一意値をグルーピングするのに対し、数値ファセットは数値を範囲ごとに分割します。ヒストグラムとして表示され、範囲内をドラックして設定できます。最小値/最大値のスライダーを動かすと、指定した範囲に絞った絞り込みが可能です。OpenRefine は例として 19 分割の等間隔ゾーンを自動で生成します。
空白・非数値・エラーの値を含めるか選択でき、それらは表示内に “0” のカテゴリとして現れます。
数値を文字列として扱いたい場合にはテキストファセットを作るとよく、たとえば範囲ではなくカウント順で並べたいときや、カウントをコピーしたいときに便利です。
前述のとおり、ファセットは GREL expressions を使って自由にカスタマイズできます。たとえば row.index/100 で行番号をグルーピングしたり、max(row.index, 1000) で 1000 より大きい数値を見やすくしたりできます。
Timeline facet

タイムラインファセットは数値ファセットと同様にヒストグラムで表示されますが、時間順に並ぶ点が異なります。タイムラインファセットは 日付 データ型のセルでのみ動作します。
空白セルとエラーセルのカウントも表示されるため、日付の変換が正しく行われているか確認できます。
Scatterplot facet
散布図ファセットは 2 つの数値の関係を視覚化します。
一次元的な直線散布図(X/Y 軸が連続的に増加)と対数的な散布図(スケールが指数的)を選べ、45 度回転させたり、各ポイントのドットサイズを指定したりできます。これらはプレビューとファセット表示の両方で設定可能です。
散布図ファセットは任意の列から作成できますが、少なくとも 2 つの数値列が必要です。 → を選ぶと、データセット内のすべての数値列の組み合わせを比較したプレビューが表示され、それぞれの組み合わせが独立したマスとして表示されます。解析したい組み合わせのマスを選ぶと、その比較がファセットサイドバーに追加されます。

表示されたマスをクリックするとその 2 列の散布図がファセットとして現れます。マウスで内部に矩形を描くことで、その矩形に含まれる点に対応する行だけに絞り込めます。矩形は四辺をドラッグして再調整したり、新しい矩形を描いたりできます。別の散布図を追加したいときは、再びプレビューで別のマスを選びます。
複数のファセットを適用中ならば、現在一致していない点は灰色で表示されます。灰色の点だけを選んだ矩形を描いても一致する行はありません。
散布図をエクスポートしたいときは、OpenRefine が新しいタブで PNG を生成してくれるので、それを保存してください。
Custom text facet
テキストデータに一時的な変換を加えたいならカスタムテキストファセットがおすすめです。列のデータをメモリに読み込み、変換した結果でファセットを構築し、ファセット内だけに反映します。
数値データも文字列として扱ったり、“true”/“false” を返す式を使って解析できます。
→ を選ぶと expressions ウィンドウが表示され、GREL・Jython・Clojure の式を入力できます。
カスタムテキストファセットはデフォルトでは text facet と同様に動作しますが、ファセットサイドバーの項目をクリックしても列のデータ自体は編集されません。表示内容が変化するだけで、元の値は保持されます。
たとえばテキスト列の最初の語だけをファセットにしたいときは、次のようにします:
value.split(" ")[0]
split() はスペースで区切って ["Firstname", "Lastname"] の配列を作り、0番目の要素(1語目)を返します(“Mary Anne” のように複数語の場合は注意が必要です)。姓を抽出したいときは [1] を使います。
複数列を参照するファセットも作れます。たとえば “First Name” と “Last Name” があり両方の頭文字が同じ行を調べたいときは、いずれかの列でカスタムテキストファセットを作成し、次の式を使います:
cells["First Name"].value[0] == cells["Last Name"].value[0]
この式は両列の先頭文字(インデックス 0)を比較し、true/false で分けます。
テキスト操作関数は Expressions ページ で詳しく確認できます。
Custom numeric facet
数値データにも一時的な変換を加えたい場合はカスタム数値ファセットを使えます。文字列の長さ(value.length())や toNumber(value) で数値的に扱うなど、柔軟に処理できます。
→ を選ぶと expressions ウィンドウが開き、GREL/Jython/Clojure の式を入力できます。カスタム数値ファセットはデフォルトで numeric facet と同様ですが、出力値を自由に変換できます。
たとえば四捨五入した数値を扱いたいときは:
round(value)
2 つの数値列があり、各行で大きいほうを対象にしたいときは:
max(cells["Column1"].value, cells["Column2"].value)
値がべき乗分布に従うなら対数を取ると見やすくなります:
value.log()
周期性があるなら周期で割った余りをとってパターンを探せます:
mod(value, 7)
数値変換関数の詳細も Expressions ページ で確認できます。
Customized facets
Customized facets は、ワンクリックで利用できる追加のファセットで、よく使う処理を expressions で自分で組み立てる必要がないように用意されています。
Facet/Filter タブに表示されるファセットは、右側の “change” ボタンから式を編集できます。そこで expressions ウィンドウが開き、式を修正・プレビューできます。
Word facet
はテキストファセットの簡易版で、スペースで分割した各文字列をファセット項目として出力します:
value.split(" ")
コーパス内の言語の頻度分析や、複数値セルの中身を手軽に確認したいときに便利です。
Word facet は大文字と小文字を区別し、改行などではなくスペースだけで分割します。
Duplicates facet
は列内で重複する値だけを抽出し、true/false のファセットを生成します。重複していない値は false、重複している値は true になります。
実際の式は次のようになっています:
facetCount(value, 'value', '[Column]') > 1
Duplicates facet は大文字小文字を区別し、余分な空白などの見落としやすい違いを除くために、たとえば次のように式を変更できます:
facetCount(trim(toLowercase(value)), 'trim(toLowercase(value))', 'cityLabel') > 1
Numeric log facet
対数スケールは広い範囲を短くまとめるのに適しており、極端に偏った分布を平滑化できます。値が特定の範囲に集中していて長いテールがあるようなときは、 が素直な数値ファセットよりもなじみのある粒度で表示します。OpenRefine は常用対数(底 10)を使います。
たとえば さまざまな哺乳類の体重データ を見ると、0〜100 に集中しながら 35,000 の値が突き抜けているような分布になります。
| Species | BodyWeight (kg) |
|---|---|
| Newborn_Human | 3.2 |
| Adult_Human | 73 |
| Pithecanthropus_Man | 70 |
| Squirrel | 0.8 |
| Hamster | 0.15 |
| Chimpanzee | 50 |
| Rabbit | 1.4 |
| Dog_(Beagle) | 10 |
| Cat | 4.5 |
| Rat | 0.4 |
| Sperm_Whale | 35000 |
| Turtle | 3 |
| Alligator | 270 |
通常の数値ファセットだと 1,000 ごとのバケットを 36 個作るため、最初のバケットにほぼすべてのセルが入ってしまいます。対数ファセットなら視覚的に均等に配置でき、パターンの把握が容易になります。

1 限界のログファセットを使えば、1 未満(0 や負数を含む)を除外して表示できます。
Text-length facet
は各セルの文字数を数値として返し、数値ファセットとしてプロットします。式は単に:
value.length()
このファセットは、たとえば以前に分割したはずのセルがうまく分割されていないものを見つけたり、YYYY/MM/DD 形式の日付が正しく 8〜10 文字かどうか確認したりするときに役立ちます。
さらに を使うと、文字数の幅が広いデータをより操作しやすくできます。大きなテキストを 1 つのセルに詰め込んだスクレイプ結果の解析などに便利です。
Unicode character-code facet

Unicode ファセットは各文字の Unicode 十進数値 を一覧化します。テキストセルで使われている文字の数値を表示し、特殊文字や句読点、フォーマット上の問題を絞り込めます。
このファセットは数値チャートを作り、範囲を指定して絞り込むことができます。たとえば小文字は 97〜122、大文字は 65〜90、数字は 48〜57 の範囲です。
Facet by error
エラーは OpenRefine がデータ変換中に生成するデータ型です。たとえば列を数値型に変換しようとして文字列が含まれていた場合、OpenRefine は元の文字列のままにするかエラーを出力します。エラーを許可しておけば、あとからそれをファセットで抽出して修正できます。
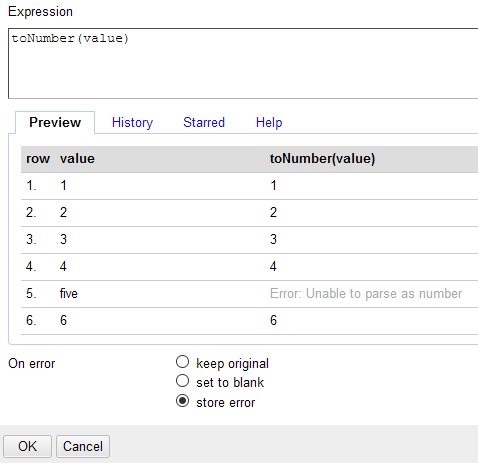
セルにエラーを記録するには、式ウィンドウの「On error」オプションで store error をオンにしてください。
Facet by null, empty, or blank
任意の列を null/空値 でファセットできます。手動で値を入力したいセルを見つけるのに便利です。
「blank」は null と empty の両方を含み、3 つとも true/false のファセットを生成し、true が空のセルとなります。
empty セルは文字列型ながら文字が 0 個(長さゼロ)の状態です。文字を削除する処理や手動編集で中身を削除すると発生します。
Facet by star or flag
スターとフラグは特定の行をマークして後から着目するためのものです。プロジェクトを閉じたり開いたりしても保持されるため、パーマリンクとは別の保存方法として役立ちます。エラーをスター/フラグしたり重要な行に印を付けたり、自由に使えます。
行の左側のアイコンをクリックするだけでスター・フラグを付けられます。
ドロップダウン(最初の列)から → / を選ぶと、現在一致する行すべてに適用されます。これにより Facet/Filter に true/false のファセットが生成され、後から解除(unstar/unflag)もできます。
ファセットを段階的に適用して条件を積み重ねた部分集合を作りたい場合、次のように進めるのも有効です:
- ファセットを適用する
- 一致した行すべてにスターを付ける
- そのファセットを解除する
- 別のファセットを適用する
- 新たに一致した行すべてにスターを付ける(既存のスターは変更されない)
- そのファセットを解除する
- 最後にすべてのスター付き行を対象に作業する
任意の列で row.starred や row.flagged の式を使ってテキストファセットを作ることもできます。
Text filter
テキストフィルターは、特定の列が文字列を含むかどうかでデータを絞り込みます。
を選ぶと、Facet/Filter タブにテキスト入力欄が表示され、文字を入力するたびに一致行が動的に狭まります。大文字小文字の区別や正規表現を使う設定もできます。
たとえば “side” と入力すると、その列に “side”、“sideways”、“offside” など “side” を含むセルだけが表示されます。
このフィルターでは 正規表現 を使えます。たとえば正しく書式化されたメールアドレスだけを残すには次の式を使えます:
([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9\-\.]+)\.([a-zA-Z0-9\-]{2,15})
“invert” を押すと空白セルや無効なメールアドレスだけが表示されます。
このフィルターはサイドバーに表示されている限り常に有効です。リセットすると入力した文字列や式が削除されます。
複数のテキストフィルターを連続で適用すると段階的に絞り込めます。たとえば “yes” と “maybe” を除外する反転フィルターを順番にかけて、残りの回答だけを見ることも可能です。