データの転置
概要
これらの機能は、行に並んだ値を列に移したり、その逆を行ったりするなど、データの形状変更で頻出する課題を解決するために用意されています。繰り返し値のセットを複数列に展開することも可能です。
列をまたぐセルを行に転置する
次のように住所情報を複数列に持つ個人データを想像してください。
| Name | Street | City | State/Province | Country | Postal code |
|---|---|---|---|---|---|
| Jacques Cousteau | 23, quai de Conti | Paris | France | 75270 | |
| Emmy Noether | 010 N Merion Avenue | Bryn Mawr | Pennsylvania | USA | 19010 |
この形式の住所情報を複数行へ転置できます。「Street」列のメニューから → を選びます。ダイアログでは「Street」から「Postal code」まで住所に関係する 5 列をすべて選択します。処理を開始したらプロジェクトを レコードモード に切り替え、「Name」列をキー列として行を結び付けるとよいでしょう。
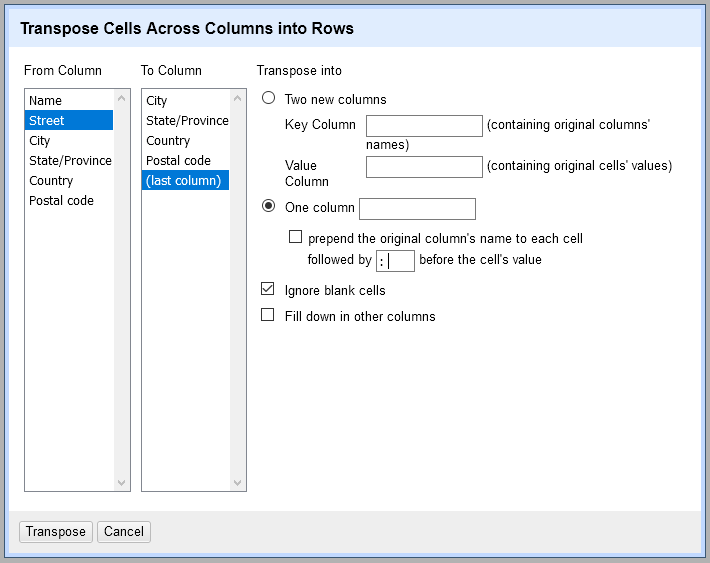
1 列にまとめる
複数の住所列を行の連なりに転置し、1 列にまとめられます。
| Name | Address |
|---|---|
| Jacques Cousteau | 23, quai de Conti |
| Paris | |
| France | |
| 75270 | |
| Emmy Noether | 010 N Merion Avenue |
| Bryn Mawr | |
| Pennsylvania | |
| USA | |
| 19010 |
1 列を指定して各セルに列名を付加することもでき、区切り文字を付けるかどうかも選択できます。
| Name | Address |
|---|---|
| Jacques Cousteau | Street: 23, quai de Conti |
| City: Paris | |
| Country: France | |
| Postal code: 75270 | |
| Emmy Noether | Street: 010 N Merion Avenue |
| City: Bryn Mawr | |
| State/Province: Pennsylvania | |
| Country: USA | |
| Postal code: 19010 |
2 列に分ける
列名を独立したセルとして残したい場合は Two new columns を選択し、キー列と値列に名前を付けます。
| Name | Address part | Address |
|---|---|---|
| Jacques Cousteau | Street | 23, quai de Conti |
| City | Paris | |
| Country | France | |
| Postal code | 75270 | |
| Emmy Noether | Street | 010 N Merion Avenue |
| City | Bryn Mawr | |
| State/Province | Pennsylvania | |
| Country | USA | |
| Postal code | 19010 |
行内のセルを列に転置する
次のように 1 列へ情報が連なっている従業員データを例にします。
| Column |
|---|
| Employee: Karen Chiu |
| Job title: Senior analyst |
| Office: New York |
| Employee: Joe Khoury |
| Job title: Junior analyst |
| Office: Beirut |
| Employee: Samantha Martinez |
| Job title: CTO |
| Office: Tokyo |
目的は 1 列に詰め込まれた情報を人ごとに整理しつつ複数列へ展開することです。
| Name | Job title | Office |
|---|---|---|
| Karen Chiu | Senior analyst | New York |
| Joe Khoury | Junior analyst | Beirut |
| Samantha Martinez | CTO | Tokyo |
→ を選ぶと、何行を 1 レコードとして転置するかを入力するダイアログが表示されます。この例では従業員 1 人につき 3 行なので「3」と入力します(元の列を差し引く必要はありません)。元の列は削除され、列名に通し番号を付けた新しい 3 列に置き換わります。
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| Employee: Karen Chiu | Job title: Senior analyst | Office: New York |
| Employee: Joe Khoury | Job title: Junior analyst | Office: Beirut |
| Employee: Samantha Martinez | Job title: CTO | Office: Tokyo |
必要に応じて → で “Employee: ” や “Job title: ”、“Office: ” を削除するか、 → で 式 を使って不要な文字を取り除きます。
value.replace("Employee: ", "")
1 レコードあたりの行数が一定でなく、生成する列数を指定できない場合は を試してください。
キー/値列で列化する
キー列と値列を持つデータセットでは、この操作で形を変えられます。キー列にある繰り返しの文字列が新しい列名になり、値列の内容がそれぞれの新列へ移動します。この操作は → にあります。
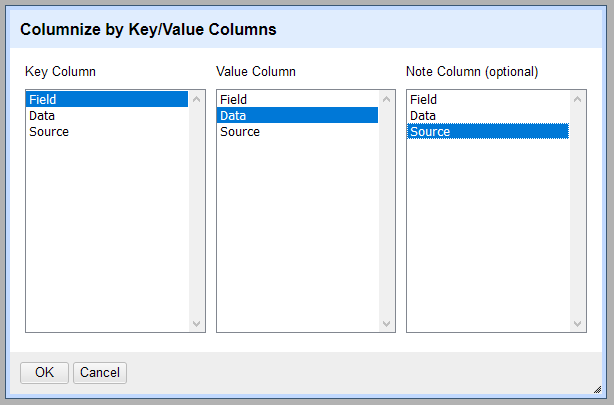
以下は花の名前、花の色、IUCN での識別子を含む例です。
| Field | Data |
|---|---|
| Name | Galanthus nivalis |
| Color | White |
| IUCN ID | 162168 |
| Name | Narcissus cyclamineus |
| Color | Yellow |
| IUCN ID | 161899 |
この形式では、各花の種が連続する複数行で記述されています。「Field」列にキーが、「Data」列に値が入っています。 ウィンドウでそれぞれの列を指定すると、表は次のように変換されます。
| Name | Color | IUCN ID |
|---|---|---|
| Galanthus nivalis | White | 162168 |
| Narcissus cyclamineus | Yellow | 161899 |
同じ列に複数の値がある場合
あるキーに複数の値が対応している場合、それらは連続する行にまとめられ、レコード構造 を形成します。
たとえば花が複数の色を持つ場合を考えます。
| Field | Data |
|---|---|
| Name | Galanthus nivalis |
| Color | White |
| Color | Green |
| IUCN ID | 162168 |
| Name | Narcissus cyclamineus |
| Color | Yellow |
| IUCN ID | 161899 |
この表を列化すると次のようになります。
| Name | Color | IUCN ID |
|---|---|---|
| Galanthus nivalis | White | 162168 |
| Green | ||
| Narcissus cyclamineus | Yellow | 161899 |
操作が最初に見つけるキーがレコードの区切りとして使われるため、「Green」は「Galanthus nivalis」に結び付きます。行順が結果へ与える影響については 行順 を参照してください。
メモ列
キー列と値列に加えて、任意でメモ用の列を指定できます。キー/値ペアに関連するメタデータを保持する用途に便利です。
次の例を見てみましょう。
| Field | Data | Source |
|---|---|---|
| Name | Galanthus nivalis | IUCN |
| Color | White | Contributed by Martha |
| IUCN ID | 162168 | |
| Name | Narcissus cyclamineus | Legacy |
| Color | Yellow | 2009 survey |
| IUCN ID | 161899 |
「Source」列をメモ列に選ぶと、表は次のように変換されます。
| Name | Color | IUCN ID | Source: Name | Source: Color |
|---|---|---|---|---|
| Galanthus nivalis | White | 162168 | IUCN | Contributed by Martha |
| Narcissus cyclamineus | Yellow | 161899 | Legacy | 2009 survey |
このようにメモ列を使えば、特定のキー/値ペアに紐づく出典や文脈を残しておけます。
行順
キー/値ペアの並び順も重要です。列化操作は最初に見つけたキーを区切りとして扱い、そのキーが再び現れるたびに新しい行を作り、その後ろのキー/値ペアをその行に追加します。
次の表を例に取ります。
| Field | Data |
|---|---|
| Name | Galanthus nivalis |
| Color | White |
| IUCN ID | 162168 |
| Name | Crinum variabile |
| Name | Narcissus cyclamineus |
| Color | Yellow |
| IUCN ID | 161899 |
「Field」列に現れる “Name” がレコードの境界を決めます。「Crinum variabile」と「Narcissus cyclamineus」の行の間に別の行がないため、「Crinum variabile」の「Color」と「IUCN ID」は空のままになります。
| Name | Color | IUCN ID |
|---|---|---|
| Galanthus nivalis | White | 162168 |
| Crinum variabile | ||
| Narcissus cyclamineus | Yellow | 161899 |
追加列がある場合は行順への敏感さがなくなり、最初の追加列が新しい行のキーとして扱われます。
追加列
キー・値・メモ以外の列がある場合でも保持できます。そのためには、新しい行にまとめられる元の行すべてで、その列の値が同じである必要があります。
次の例では「Field」がキー、「Data」が値として使われ、「Wikidata ID」は選択されていません。
| Field | Data | Wikidata ID |
|---|---|---|
| Name | Galanthus nivalis | Q109995 |
| Color | White | Q109995 |
| IUCN ID | 162168 | Q109995 |
| Name | Narcissus cyclamineus | Q1727024 |
| Color | Yellow | Q1727024 |
| IUCN ID | 161899 | Q1727024 |
変換結果は次のとおりです。
| Wikidata ID | Name | Color | IUCN ID |
|---|---|---|---|
| Q109995 | Galanthus nivalis | White | 162168 |
| Q1727024 | Narcissus cyclamineus | Yellow | 161899 |
この場合、OpenRefine は最初に現れるキー(“Name”)ではなく、最初の追加列の値を基準にして情報をまとめます。同じ値を持つ元の行は 1 つの新しい行に転置されます。追加列が複数あっても同様にピボットされますが、新しいキーにはなりません。
必要であれば を使って追加列の値をそろえてください。