セル編集
Overview
OpenRefine はセルの内容を自動かつ効率的に編集・改善するためのさまざまな機能を備えています。
一例として テキストファセット を使った編集があります。列にファセットを作成したらサイドバーに表示された結果にマウスを合わせ、ファセットの右側に現れる小さな “edit” ボタンをクリックし、新しい値を入力すると、そのファセットに含まれるすべてのセルに適用されます。
数値・真偽値・日付に対してもテキストファセットを使えますが、値を編集するとその値はテキストの データ型 に変換されます(たとえば日付を別の正しい形式の日付に変えても、「true」を「false」に変えても、結果はテキストとして扱われます)。
Transform
→ を選ぶと式ウィンドウが開き、そこから expressions でデータに変換を適用できます。最も単純な例は toUppercase() や toLowercase() のような GREL 関数で、式では toUppercase(value) や toLowercase(value) のように書きます。列操作で使用すると、value は選択中の列の各セルの値を表します。
プレビューを使ってデータが意図どおり変換されているか確認してください。
式ウィンドウ内の Undo / Redo タブに切り替えると、すでにこのプロジェクトで試した式を、取り消したかどうかにかかわらず再利用できます。
OpenRefine には次のメニューオプション で頻出の変換がまとめられています。より柔軟な変換が必要な場合は expressions を参照してください。
Common transforms
Trim leading and trailing whitespace
見た目が同じでも、目に見えない空白や改行文字が入っているせいでセルが異なる場合があります。この操作は、表示される文字の前後にある余分な文字を取り除きます。
Collapse consecutive whitespace
セル内に見た目では空白に見えるものの実際にはタブだったり、複数の空白が連続していたりする場合があります。この操作は連続した空白文字をすべて削除し、1 つのスペースに置き換えます。
Unescape HTML
データが HTML 形式で、一部の文字を “ ” や “%u0107” のような参照で表現している場合があります。「unescape HTML entities」変換を使えば、これらのコードを検出し、対応する Unicode 文字に置き換えられます。他の書式でエスケープが必要な場合は escape() を使ったカスタム変換を試してください。
Replace smart quotes with ASCII
スマートクォート(カーブした引用符)は文字列の先頭と末尾を識別して「開き」や「閉じ」を出し分けますが、ASCII には含まれません(UTF-8 では問題ありません)。この変換を使うと、直線的な二重引用符 (") に置き換えられます。
Case transforms
これらのオプションで列全体を大文字・小文字・タイトルケースに変換できます。文字列の分析を予定していてケース感度のある関数で問題が発生しそうな場合に役立ちます。必要に応じて、この恒久的な操作ではなく、カスタムファセット を使って一時的にケースを変更することも検討してください。
Data-type transforms
Data types で詳述しているように、OpenRefine は文字列・数値・真偽値・日付などのデータ型を識別します。これらの変換を使うと、与えられた値が変換可能かを判定したうえでセルの内容(例:「3」というテキストを「3」という数値に)を変換し、変換に成功したセルではデータ型も更新されます。変換できなかったセルは元の値と型を維持します。
日付の変換では手作業の介入が必要になることがあります。Dates セクションを参照してください。
これらの共通変換は元のセル内容の代わりにエラーを出力する機能を持たないため、変換されていないセルが残っていないか注意深く確認してください。画面上部に黄色の警告が現れ、何個のセルが変換されたかを示します。この数が現在表示中の行数と一致しない場合は、残ったセルを手動で修正する必要があります。また、GREL 関数 type() を使ってデータ型ごとにファセットを作成することも検討してください。
セルを null 値や空文字列に変換することもできます。たとえば、すでに特定した重複を消してそのサブセットをさらに調べたい場合に役立ちます。
Fill down and blank down
Fill down と blank down は、1つの実体に関連する複数行(records)に遭遇したときによく使う操作です。
行モードでデータを受け取り、レコードモードに変換したい場合は、最初の列を固有のレコードキーとして使いたい値でソートし、そのソートを確定 したあとでその列の重複をすべて blank down してください。OpenRefine は最初の一意な値を残し、その他を消去します。続いて「Show as rows」から「Show as records」に切り替えると、1列目に残った値に基づいて行同士を結びつけます。
blank down を始める前には、対象列だけでなく、特定の順序にしたい他の列の値も含めてデータが正しくソートされていることを確かめてください。たとえば最初の列に同じ値が複数あり、2列目に値がある行と空白の行がある場合は、2列目に値がある行が先に来るように並べておくと、後から空行を片付けやすくなります。
逆に、すでにレコードモードのような形式で空白セルがあるデータを受け取った場合は、残りの行に対して fill down で情報を流し込めます。これは最上位の値が入ったセルを見つけ、その値を下の行に複製していく操作です。最初の行が空白ならその下、さらにその下…と値を探してコピーします。上部の空白セルはそのまま残ります。
Split multi-valued cells
1つのセルに複数の値が含まれる場合、それを分割して 複数行のレコード にするのがよくあるパターンです。たとえば調査データでは「該当する項目すべてを選択」できたり、在庫リストではアイテムが複数カテゴリに分類されていたりします。
セミコロン (;) やスラッシュ (/) など任意の文字または文字列で列を分割できます。デフォルトはカンマです。区切り文字で分割するとその文字は除去されるため、データに空白付きの区切りが含まれるなら ; のようにスペースも合わせて指定するとよいでしょう。
expressions を使えばセルをどの地点で複数行に分割するかを細かく制御できます。特殊文字を検出したり高度な条件を組み込んだりするのに役立ちます。改行で分割したい場合は \n と入力し、「正規表現」チェックボックスをオンにしてください。
単純でない分割には正規表現が有効です。たとえば大文字 ([A-Z]) が新しい文字列の始まりを示す場合や、区切り文字と文字列の両方に現れる文字を常に分割したくない場合に使えます。ただし一致した文字はすべて削除されるので注意してください。
文字列の長さを基準に分割することもできます。たとえば10桁の電話番号、スペース、別の10桁の電話番号という規則性があるデータでは便利です。指定した長さを超える文字は破棄されます(たとえば「11, 10」で分割すると21文字目以降は消えます)。1つの電話番号しか含まれないセルでは空行になることがあります。
値を複数列に分割したい場合は Split into several columns を参照してください。
Join multi-valued cells
これまでの分割処理の逆で、複数の行の情報を1行にまとめます。文字列は出現順にレコードの最上位セルに圧縮されます。ウィンドウが開き、区切り文字を指定できます(デフォルトはカンマと空白 , )。この区切り文字は任意で、希少な文字 | を使うのもよいでしょう。
Cluster and edit
列にファセットを作成するとデータの不整合が見つけやすく、クラスタリングはそれらを修復する手段です。クラスタリングは似ていて完全に一致しないテキストを比較し、その結果を提示してマージすべきセルを選べるようにします。1つずつセルやファセットを編集するより、クラスタリングのほうが迅速かつ効率的です。
クラスタリングは提案された編集を必ずユーザーが承認する必要があります。OpenRefine は同じもののバリエーションだと思われる値を提示し、どのバージョンを残して一致するすべてのセルに適用するか(あるいは独自の値を入力するか)を選べます。
OpenRefine は分析前にいくつかのクリーニング処理を自動で行いますが、実際にデータを変更するのは承認したマージだけです。その仕組みを理解すると、どのクラスタリング手法を使えば精度と効率のバランスがとれるか判断しやすくなります。
プロセスは2通りの方法で開始できます。列のドロップダウンメニューから → を選ぶか、テキストファセットを作成してファセットボックスに現れる「Cluster」ボタンを押してください。
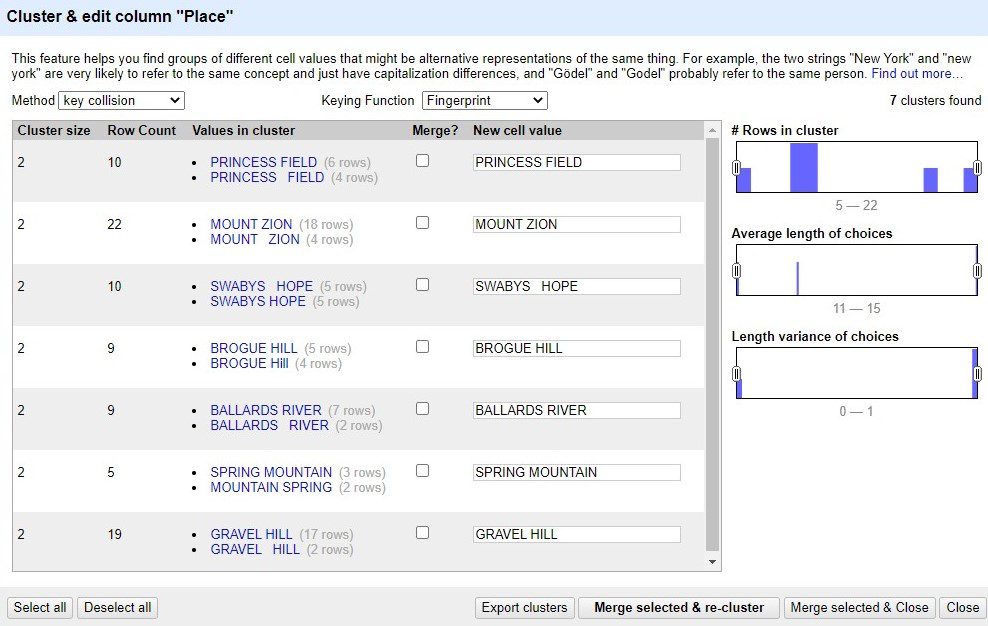
クラスタリングのポップアップは列を解析するのに少し時間がかかり、現在選択されている手法に基づいた候補を提示します。
識別された各クラスタに対して既存の値を選んで全セルに適用するか、テキストボックスに新しい値を入力するかを選べます。もちろんクラスタリングせずにそのままにすることもできます。 を使えば変更ごとに再解析が行われ、すべての手法を順番に試せます。
現在のクラスタを JSON ファイルとしてエクスポートしたり、変更の有無にかかわらずウィンドウを閉じたりすることもできます。右側のヒストグラムで一致行の多いクラスタや文字数の長い/短いクラスタに絞り込むことも可能です。
Clustering methods
各クラスタリング手法の詳細を完璧に理解していなくても、データに適用できます。
インターフェースやこのページでの手法の順番は、より厳密なルールから緩いルールへと進む順序で、最初は厳格な手法を試し、緩い手法は人の目で確認しながら使うのが望ましいです。
クラスタリングポップアップは2つのカテゴリを提供します。6種類の Key Collision(キー衝突)クラスタリングと、2種類の Nearest Neighbor(最近傍)クラスタリングです。
-
Key Collision カテゴリはさらに phonetic と非 phonetic に分類されます。
Key Collision
Key Collision は非常に高速で、何百万セルでも数秒で処理できます。
Fingerprinting は偽陽性(false positive)が最も少ないため安心して最初に試せる手法で、あなたが手作業で行いがちなデータクリーンアップと同じような処理を裏で実行します。
- 空白を単一のスペースに統一する
- すべての大文字を小文字にする
- 句読点を取り除く
- 文字からダイアクリティカル記号(例:アクセント)を削除する
- 文字列(単語)を分割してアルファベット順に並べる(例:「Zhenyi, Wang」は「wang zhenyi」になる)
Fingerprinting の理論的な背景は この文書 を参照してください。
N-gram フィンガープリンティングでは n を任意の値に設定し、n 文字の n-gram を作成して(前処理のあと)アルファベット順に並べ直し、再び連結してフィンガープリントを構築します。
たとえば 1-gram フィンガープリントならセル内の文字をすべて 1 文字ずつのセグメントとして取り出し、アルファベット順に並べていくだけです。2-gram フィンガープリントでは 2 文字のセグメントをすべて拾い、重複を取り除き、並び替えて連結します(例:「banana」から「ba an na an na」が生成され、「anbana」になります)。
これにより誤字や不適切なスペース(たとえば「lookout」と「look out」のようなケース)を同じクラスタにまとめやすくなります。n を大きくすると認識されるクラスタ数は減ります。1-gram では、互いに近いアナグラム(例:「Wellington」と「Elgin Town」)に注意してください。
N-gram フィンガープリンティングについて詳しくは この文書 を参照してください。
次に紹介する4つの手法は音声的アルゴリズムで、発音したときに同じ音になる文字を識別し、それに基づいてテキストを評価します(たとえば “S” が “Z” の誤記かもしれないと認識します)。言葉や名前を聞いてからつづりを知らないときに起きるミスを見つけるのに非常に有効です。
Metaphone3 は英語の発音に対応した音声アルゴリズムです。たとえば “Reuben Gevorkiantz” と “Ruben Gevorkyants” は英語において同じ音声フィンガープリントを共有します。
Cologne はドイツ語の発音に対応した別の音声アルゴリズムです。
Daitch-Mokotoff はスラブ語やイディッシュ語の名前など、特定の語彙に特化した音声アルゴリズムです。
Baider-Morse は Daitch-Mokotoff を少し厳格にしたバージョンです。
データの言語にかかわらずすべての手法を順番に試すことで異なる候補が見つかることがあります。たとえば Metaphone では “Cornwall”、“Corn Hill”、“Green Hill” をまとめますが、Cologne では “Greenvale”、“Granville”、“Cornwall”、“Green Wall” をまとめる、といった違いです。
音声アルゴリズムの詳細は この文書 を参照してください。
Nearest Neighbor
Nearest Neighbor は Key Collision より処理が遅いです。
この手法では一致するかどうかのしきい値(radius)を設定できます。OpenRefine は最初に “blocking” を実行し、一定の類似度(デフォルトでは6文字の同一文字列)を持つ値をソートし、そのグループ内で最近傍の比較を行います。
ブロック数は少なくとも3に設定し、それでも広すぎる場合は厳しくするために 6 以上に増やすことをおすすめします(たとえば「river」が含まれるすべての値が一致してしまうなら増やしてください)。
注意: ブロック値を大きくすると処理に時間がかかり、小さくするとマッチし損ねる可能性があります。radius を増やすとより離れた値同士もマッチするようになり、比較的ゆるやかなクラスタになります。
Levenshtein 距離は、ある値を別の値と完全一致させるために必要な編集回数を数えます。Key Collision と同様に大文字→小文字変換、空白の調整、特殊文字の変更などを行い、変更した文字ごとに 1 の “距離” を加算します。「New York」と「newyork」は “N”→“n”、“Y”→“y”、空白の削除という3つの変更があるため距離は 3 です。
より複雑な編集、たとえば “M. Makeba” と “Miriam Makeba” の距離は 5 と計算できますが、その距離がほかの簡単な変換(たとえば全く別人の “B. Makeba” との 1 文字差)より大きいときに誤検出が発生することもあります。
PPM (Prediction by Partial Matching)
PPM は圧縮を用いて2つの値が似ているかどうかを判断します。実際には小さな radius でも緩く、多くの偽陽性を生成しがちですが、文字単位より細かいサブ文字レベルでの構造を見つけられるため、ほかの距離では見つけにくい一致を探せます。したがって“最後の手段”として使うべき手法です。また短い文字列よりも長い文字列のほうが効果的です。
クラスタリングの理論的な背景は Clustering In Depth を参照してください。
Custom clustering methods
OpenRefine の Custom Clustering では、独自のルールで類似データをグループ化できます。組み込みの手法で満足できないとき、データに合った新しいクラスタリング方法を試し、より意味のある結果を引き出すのに役立ちます。
Custom clustering 関数は GREL、Jython、Clojure のようなスクリプト言語で作成できます。これらの関数は、データをどのようにクラスタに分けるかを次の2種類の方法で定義します:
- Keying:データ値にグループ(キー)を割り当てる
- Distance:2つの値の類似性(あるいは差異)を測る
この機能を試すステップ:
- クラスタリングのインターフェースへ移動する。
- ボタンをクリックしてカスタムクラスタ関数のダイアログを開く。
- 目的の関数の種類に応じて または タブを選ぶ。
- ボタンをクリックする。
- 関数に名前を付ける。
- GREL、Jython、Clojure で式を記述する。
- と タブで実際の動作を見ながら調整する。
- 関数を保存してダイアログを閉じる。
追加したカスタム関数は keying や distance のドロップダウンに表示され、選ぶとデータに適用されます。
たとえば英語の曲名で記事(“the” や “a”)の有無により値が分かれる場合を考えてみましょう。The Peanut Vendor、Peanut Vendor (The)、Peanut Vendor のような値があり、デフォルトの fingerprinting 関数では The Peanut Vendor と Peanut Vendor (The) を peanut the vendor にまとめられますが、Peanut Vendor は peanut vendor と別のクラスタになります。これを回避するには、フィンガープリント値から記事を取り除くカスタム keying 関数を使います: filter(value.fingerprint().split(" "), word, (word != "the").and(word != "a").and(word != "an")).join(" ")。この式を使えば3つの値は同じクラスタキー peanut vendor にまとまります。
Levenshtein 距離を使った最近傍では、2つの値の差分を文字数で数えますが、文字列の長さを考慮しません。たとえば Fong と Fang は距離 1 ですが、Sinéad O'Connor と Sinéad M. O'Connor では距離 3 になります(直感的にはより似ているのに)。長さが大きく異なる文字列をクラスタリングする際は、距離を文字列の長さで正規化するとよいでしょう。たとえば levenshteinDistance(value1, value2) / (max(length(value1), length(value2)) + 1) のようなカスタム distance を使うと、Fong と Fang は 0.2、Sinéad O'Connor と Sinéad M. O'Connor は 0.16 になります。
組み込みのクラスタリング関数については Clustering In Depth を参照してください。
Replace
OpenRefine には文字列置換の操作が用意されており、 → で簡易ウィンドウが開き、検索する文字列と置換先を入力できます。大文字・小文字の区別や、スペースや句読点で囲まれた単語全体だけを対象にする設定も可能です(たとえば “doghouse” から “house” 部分だけを選ばないようにできます)。このフィールドでは 正規表現 も使えます。操作の結果は先に Text filter で試してプレビューしておくことをおすすめします。
1 つのセルを編集し、そのあと「apply to all identical cells」を選ぶことで、一括的な置換のような操作も可能です。
Edit one cell at a time
セルにマウスを合わせると小さな青い「edit」リンクが表示されます。これをクリックするとテキスト入力欄が大きく表示され、そのセルを編集できます。ポップアップ内で データ型 を変更したり、同じ列内の一致するセルすべてにこの変更を適用することもできます。
ただし、これは稀なケースに限り使い、データを改善するには自動化や一括処理のほうが効率的であることを覚えておいてください。